Vysics
Object Reconstruction Under Occlusion by
Fusing Vision and Contact-Rich Physics
(coming soon)
TL;DR: Vysics is a vision-and-physics framework for a robot to build an expressive geometry and dynamics model of a single rigid body, using a seconds-long RGBD video and the robot's proprioception.
Abstract
We introduce Vysics, a vision-and-physics framework for a robot to build an expressive geometry and dynamics model of a single rigid body, using a seconds-long RGBD video and the robot's proprioception. While the computer vision community has built powerful visual 3D perception algorithms, cluttered environments with heavy occlusions can limit the visibility of objects of interest. However, observed motion of partially occluded objects can imply physical interactions took place, such as contact with a robot or the environment. These inferred contacts can supplement the visible geometry with “physible geometry,” which best explains the observed object motion through physics. Vysics uses a vision-based tracking and reconstruction method, BundleSDF, to estimate the trajectory and the visible geometry from an RGBD video, and an odometry-based model learning method, Physics Learning Library (PLL), to infer the “physible” geometry from the trajectory through implicit contact dynamics optimization. The visible and “physible” geometries jointly factor into optimizing a signed distance function (SDF) to represent the object shape. Vysics does not require pretraining, nor tactile or force sensors. Compared with vision-only methods, Vysics yields object models with higher geometric accuracy and better dynamics prediction in experiments where the object interacts with the robot and the environment under heavy occlusion.
Architecture
The figure illustrates the overall design of Vysics from input RGBD videos and robot states (left) to URDF output (right). Its core components are BundleSDF for vision-based tracking and shape reconstruction, and PLL for physics-inspired dynamics learning. Beyond the insights that led to this systems integration, our main contribution lies in how Vysics incorporates these two powerful tools together such that they supervise each other and output an object dynamics model, featuring geometry informed by both vision and contact.
Geometry Results
Vysics trains on a seconds-long RGBD video and the robot's
proprioception. Above, see the learned geometries overlaid on the input
video with the BundleSDF tracked pose. This shows
how the physics-based reasoning helps to extend the geometry
beyond the visible regions, towards contacts PLL infers from
the trajectory. The end effector is highlighted in yellow.
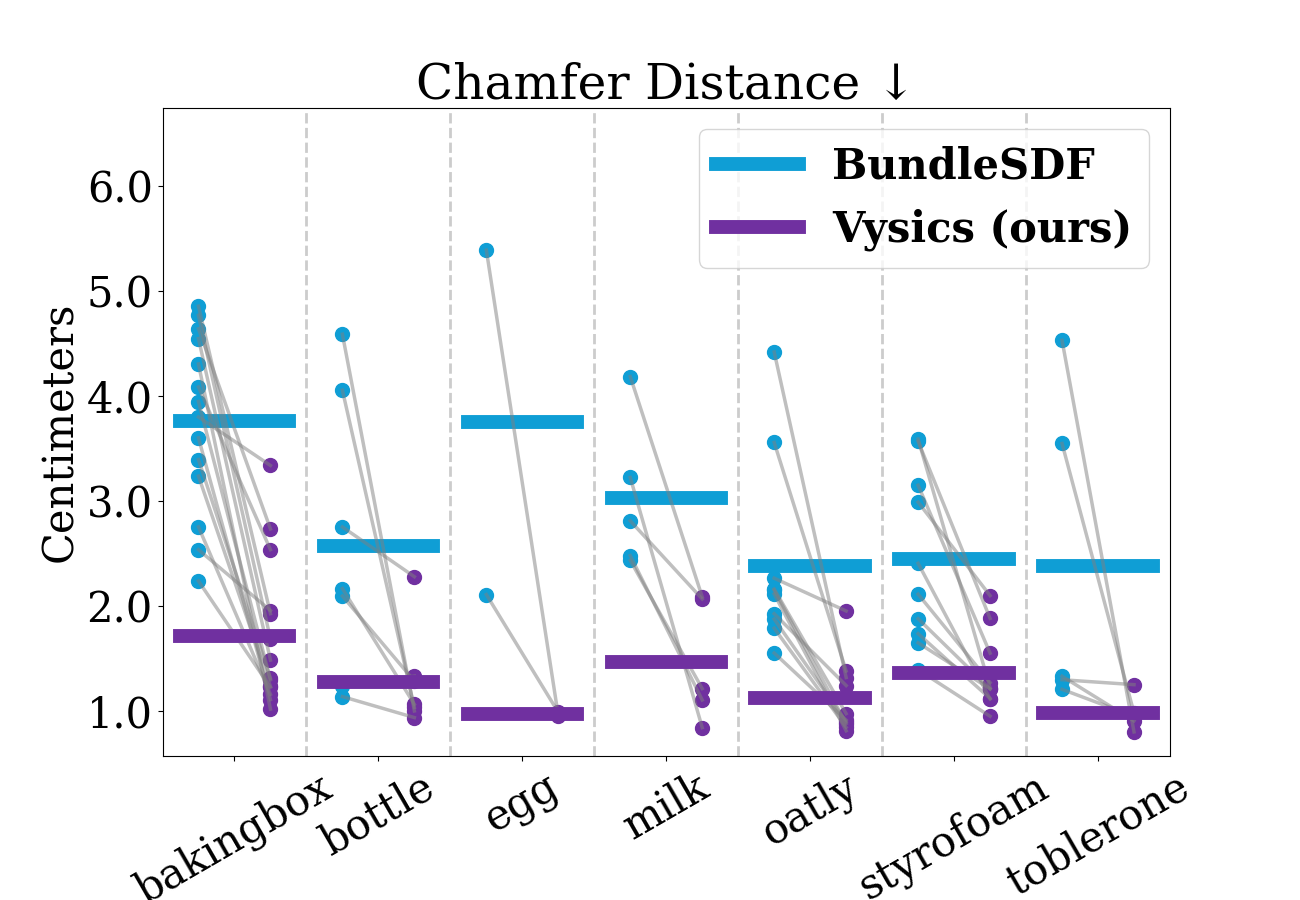
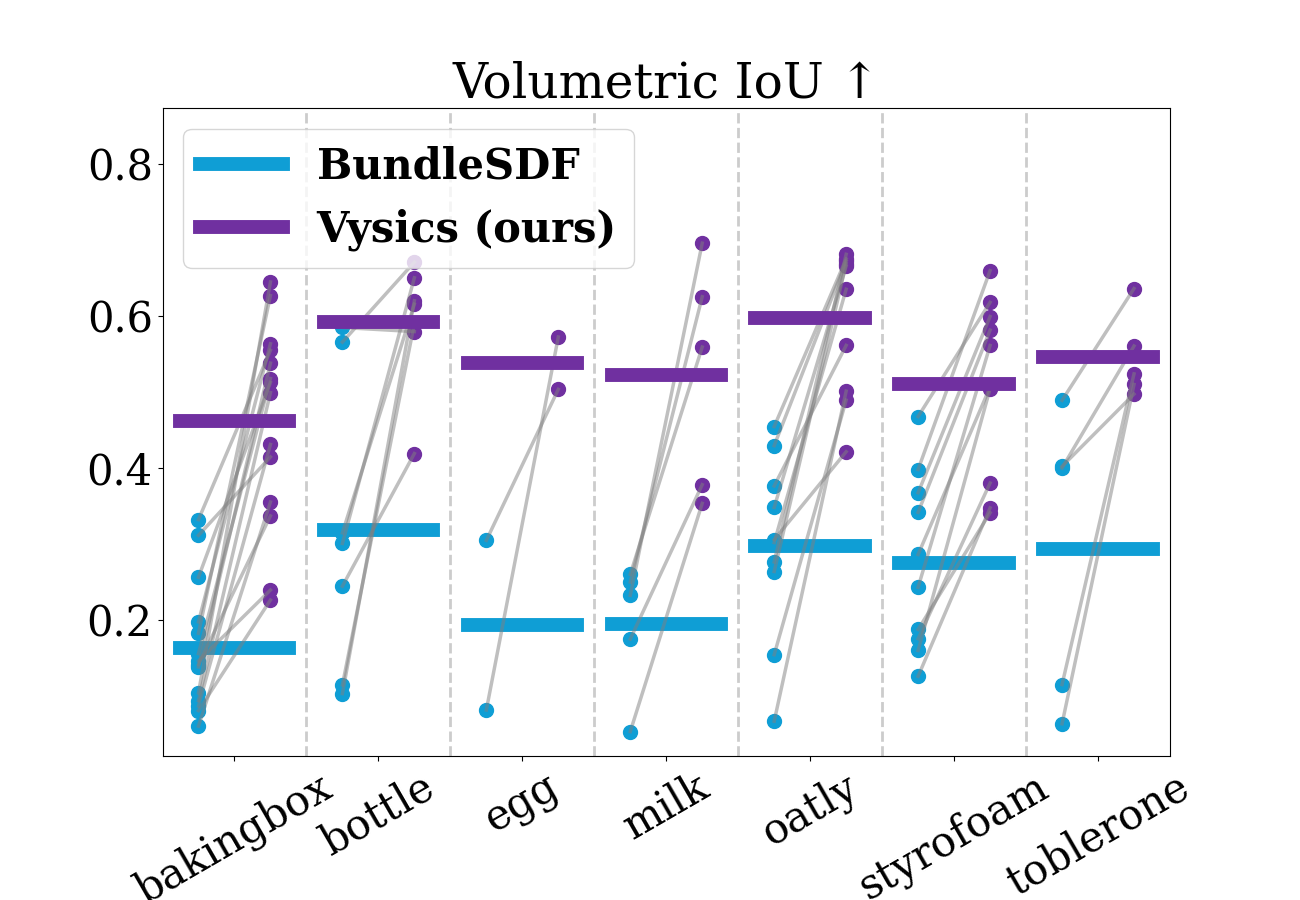
Due to severe occlusion in the RGBD videos, vision-based reconstruction yields significant errors. Our method recovers the occluded geometry through physics-based reasoning over the observed trajectories. The plots above show substantial and consistent improvements in terms of both the surface-based metric (chamfer distance) and the volume-based metric (IoU).
Each example above shows the input video, a photo of the object, and the reconstructed geometry from Vysics (which fuses vision and physics) and BundleSDF (vision-only).
Geometry Comparison to Data-Driven Shape Completion Models
While the objects are heavily occluded in the camera view, one may wonder if shape completion models, which learn prior knowledge of the shape of typical objects from a large amount of data, may recover the occluded geometry. We tested several data-driven shape completion models: 3DSGrasp for point cloud completion; IPoD for single-object completion from an RGBD image; and V-PRISM and OctMAE for multi-object scene completion from an RGBD image. See the below table for results, showing Vysics outperforms all other baselines for each object in our dataset and overall.
Table 1: Chamfer Distance (cm)
| Method | bakingbox | bottle | egg | milk | oatly | styrofoam | toblerone | all |
|---|---|---|---|---|---|---|---|---|
| BundleSDF | 3.84 | 2.65 | 3.70 | 3.17 | 2.45 | 2.55 | 2.44 | 2.98 |
| 3DSGrasp | 3.83 | 2.80 | 3.78 | 3.15 | 2.51 | 2.66 | 2.77 | 3.06 |
| IPoD | 3.25 | 1.80 | 2.16 | 2.37 | 2.73 | 1.93 | 1.97 | 2.47 |
| V-PRISM | 3.52 | 2.47 | 2.31 | 3.33 | 2.30 | 2.54 | 2.48 | 2.80 |
| OctMAE | 3.11 | 2.22 | 1.52 | 2.93 | 2.13 | 2.00 | 2.36 | 2.45 |
| Vysics (ours) | 1.83 | 1.36 | 1.05 | 1.53 | 1.25 | 1.45 | 1.02 | 1.45 |
Dynamics Predictions
Because Vysics uses physics reasoning to inform the recovered geometry, it enables accurate dynamics predictions when predicting the original trajectory. To do this, we simulate the recorded robot commands in a simulator with the learned object model, then we compare the resulting object trajectory to the BundleSDF trajectory estimate. The videos above show the simulation results of Vysics models compared to vision-only geometry (from BundleSDF), physics-only geometry (from PLL), and the ground truth geometry (from a 3D scanner).
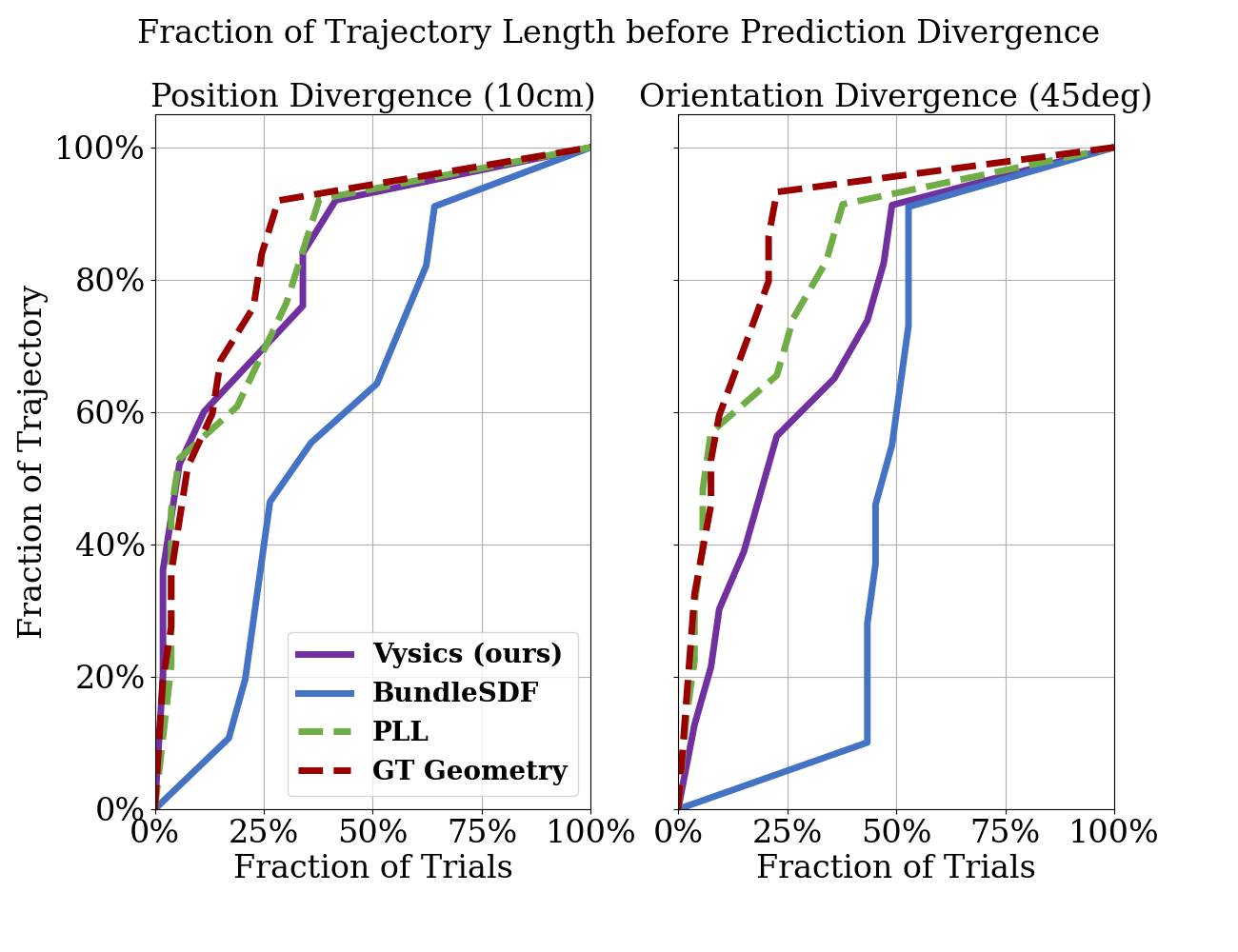
The plot above shows the average position and rotation errors when predicting the entire length of the original trajectory as an open-loop rollout, averaged for every example and result in the dataset. The trajectories range in length from 3 to 18 seconds. Even the ground truth geometry baseline is imperfect, due to inaccurate modeling assumptions such as object rigidity and the divergent nature of the dynamics in many of our robot interactions. Vysics and PLL perform closely to this baseline. While most of the dynamics performance by PLL is retained in Vysics, it is unsurprising to see a slight performance drop, given PLL optimizes only for physics accuracy while Vysics balances with visual objectives. The vision-only baseline is the least performant in both position and orientation rollout accuracy.
Acknowledgments
We thank our anonymous reviewers, who provided thorough and fair feedback that improved the quality of our paper. This work was supported by a National Defense Science and Engineering Graduate (NDSEG) Fellowship, an NSF CAREER Award under Grant No. FRR-2238480, and the RAI Institute.
Citation
If you find this work useful, please consider citing: (bibtex)
@inproceedings{bianchini2025vysics,
title={Vysics: Object Reconstruction Under Occlusion by Fusing Vision and Contact-Rich Physics},
author={Bibit Bianchini and Minghan Zhu and Mengti Sun and Bowen Jiang and Camillo J. Taylor and Michael Posa},
year={2025},
month={june},
booktitle={Robotics: Science and Systems (RSS)},
website={https://vysics-vision-and-physics.github.io/},
}